Java OpenID Library - Target Audience
One of the decisions that has to be made, or at least considered, early in the design of any software project is identifying your target audience. This is especially true of libraries that are designed to be integrated into other applications. Who do you expect to be using this library, and how do you expect them to make use of it? Is it something like log4j that can be dropped into place and used with just a few lines of additional code? Or is it something that is intended to be integrated into a larger system, requiring the developer using the library to provide additional logic and business rules to get things working? Something that might require a non-trivial amount of effort, depending on the needs of the use-case. There is no right or wrong answer, and oftentimes it’s somewhere in between, but it’s something that must be considered.
Some of the best software libraries I’ve used address both ends of the spectrum. There’s a common adage in software development (and I’m sure it goes back farther than that): “make the common things easy, and the hard things possible”. First, you don’t want to make things any harder than necessary for the majority of users that are just using the basic functionality of a library. If they don’t care about customizing and tweaking every little aspect of it, then the way they interact with the library should be relatively simple and straightforward. But for those users that have unique needs, the library should allow them to configure it in such a way to accommodate that. It is certainly my goal to address both extremes in the Shibboleth OpenID library, but it will happen in phases.
The first phase will address the edge-cases, those users of the library that tend to have unique needs and requirements. That may seem backwards, but I assure you it isn’t. First of all, the really practical reason for starting here is that Shibboleth is itself an edge case. The reason I chose not to use the existing Java OpenID libraries in the first place was that they didn’t adequately conform to the way Shibboleth needed them to work. But from a design perspective, I’ve found that this approach tends to yield better results anyway.
Small Pieces Loosely Coupled
I’ve learned that in order to make a system really flexible and modular, it’s best to architect it that way from the very beginning. You have to decide where the logical divisions of labor are within the system, and then translate that into the code itself. Each component should be relatively self-contained, it’s purpose should be clear, and its interface (the way it interacts with other components) should be separated from its actual implementation. Sometimes these components are obvious, and there are clear places where the code should be divided. But more often than not, its a judgement call. Architecture is often harder than actual construction, whether you’re talking about software or brick and mortar. It requires a lot of creativity because you’re often working from a blank canvas, but it also requires that your plans are grounded in what is actually possible. Architectural plans are worthless if they can’t actually be implemented in the real world in a practical way. By no means do I think that I’ve found the best architecture for this library, because it’s always subjective. Fortunately, I’ve had similar libraries that I’ve borrowed from heavily for inspiration, as well as much smarter developers that I work with to bounce ideas off of.
At its core, this library is an OpenID messaging library. It is capable of converting between generic HTTP messages and strongly typed OpenID objects that developers can work with. My last two posts have talked about this in detail. The library also provides the additional logic for implementing the OpenID specification, things like Diffie Hellman key exchange and OpenID message signing. What the library does not do is tell you how you must compose these pieces into a working system. That’s because there isn’t just one way to do it. It greatly depends on the application that is wanting to add OpenID support. If you’re using a Java framework like Tapestry or JSF, perhaps you have other processing that happens to the message before the OpenID library gets involved. How does the user get authenticated and where do the user attributes come from? I have no idea… that’s up to your application to decide. At this level, the library makes no assumptions (or at least as few as possible) about how all of these small pieces should be coupled together.
If this sounds like a lot of work left up to the user just for something as simple as OpenID, you’re right… it is a lot of work. But when you really need that level of control, it’s important that the library support that.
Addressing the Common Case
So what about everyone else, all the “mere mortals” who don’t need that much control, and just want to add OpenID support to some application using the default configuration? At a high level, I’d love to have a Servlet Filter that you can drop in front of your application, configure a few small things, and have it just work as an OpenID relying party. I’ve always been a huge fan of the Tapestry framework, so I’d love to have a Tapestry component that can be dropped in just as easily. All of these things are possible by building a layer that sits on top of those individual components in the library, and arranges them in a prescribed way.
Now, I don’t anticipate that a drop-in Servlet Filter will ever be a part of the core library, because I don’t think it belongs there. It would be a separate deliverable unto itself that simply relies on the library to do all of OpenID work. This also means that the Filter wouldn’t necessarily need to come from me, anyone could write it and make it available. I don’t imagine that the core library itself will ever have everything that the “common case” users will need. And I’m okay with that, because I’m not building an OpenID product, I’m building an OpenID library.
Current Status
This is by no means a complete picture of the Shibboleth OpenID library, but it should give you a rough idea. It identifies some of the larger components of the libraries, and some of the interdependencies.
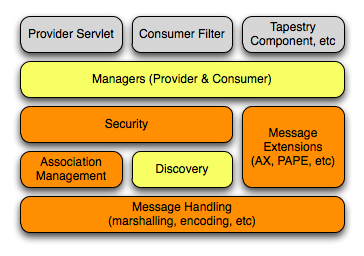
The orange blocks are pieces that are basically complete and present in the current library. All of the message handling is complete for OpenID 2.0 message, as well as three of the most popular message extensions (SReg, AX, and PAPE). Additionally, association management is done, and a very simple AssociationStore is provided (though it needs a little improvement). The security layer is complete insofar as signing and verifying signed messages. The yellow blocks represent pieces that are not yet complete, but will be included in the core library in the future. The discovery component is still up in the air a little bit because it’s not completely clear if we’ll be using XRD, XRDS, or both. The portions of the security layer that depend on discovery are, of course, waiting on the completion of the discovery stack. Those pieces include everything that an application would need to construct an OpenID provider or relying party. They implement the full OpenID protocol.
But those components alone leave a lot to be filled in by the application using the library. It says nothing about how an incoming HttpServletRequest object is converted into an OpenID Message. The application would be responsible for instantiating the specific objects and wiring them together to actually get a working AssociationManager. And for applications that wish to have control over these specific aspects of an OpenID flow, this is a good thing. The next layer up on the stack however, the yellow “Managers” block, will provide simple Manager objects that wire things together in a prescribed way. Most users of the library will deal with the Manager layer, and probably nothing else. Only when they have specific needs will it be necessary to dig any deeper.
Now this last layer is actually nothing special… it’s a very common pattern, and both OpenID4Java and Joid work in very similar ways. I point it out only to note that while this layer will be part of the core library in a future release, it isn’t right now. Much of the code that will likely make up these components has already been written, but in the form of the Shibboleth IdP extension. For the last few months I’ve been simultaneously building both a generic OpenID library, as well as an actual product that makes use of the library. One of the tougher ongoing challenges while doing this is in deciding which of the two projects a particular bit of code goes into. Much of the time it’s clear, but when in doubt, I’ll put something into the Shibboleth extension rather than the library. If anything, I want to err on the side of keeping the library “pure” so to speak. To not accidentally bake any assumptions into the library itself that might limit its flexibility. One of my focuses after the holidays will be in identifying which pieces need to be refactored from the Shibboleth extension back into the core library in order to build out that management layer.
(And in case it’s not clear, the final layer in grey in the stack above are other pieces that will make use of the OpenID library, but will likely not be part of the library itself.)